


Cloudflare, a global leader in internet infrastructure and security, has publicly alleged that artificial intelligence search engine Perplexity is using stealth tactics to bypass standard website directives that are meant to block unauthorized bot access.
Key Allegations
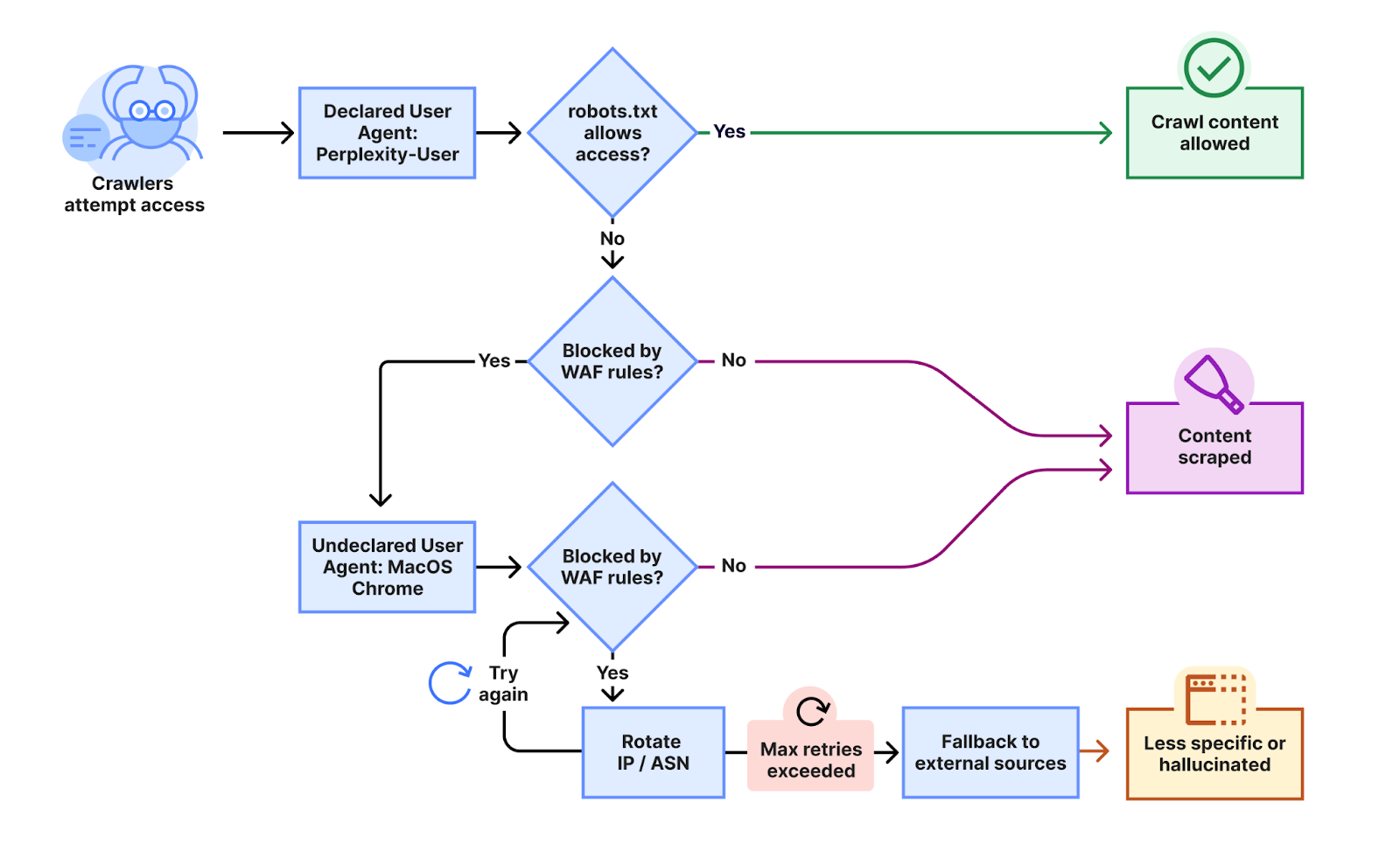
Cloudflare’s technical team received repeated complaints from website operators who reported that, despite taking steps to forbid Perplexity’s web crawlers—including updating their robots.txt files and implementing firewall rules—the company’s content was still being accessed. Robots.txt is a long-standing internet standard that allows website owners to control how and whether automated bots can crawl their properties.
In an in-depth investigation, Cloudflare claims it discovered that:
- Perplexity initially sends requests identifying as its official bots (“PerplexityBot” or “Perplexity-User”).
- If those requests are blocked, Perplexity allegedly switches tactics: it modifies its user agent (the digital fingerprint indicating whether a browser is human or bot), impersonating something like “Google Chrome on macOS,” and uses rotating IP addresses that are not on its documented lists.
- The approach includes changing Autonomous System Numbers (ASNs) – identifiers that help track which networks the traffic originates from – in order to further disguise the activity and bypass network restrictions.
- This “stealth crawling” reportedly affects tens of thousands of domains and generates millions of requests daily.
Industry and Ethical Implications
Cloudflare’s findings underscore a growing concern in the technology industry regarding compliance with established web norms. The Robots Exclusion Protocol, formalized as an internet standard, is widely recognized by responsible search engine companies and bot operators worldwide.
Cloudflare, in response, has de-listed Perplexity as a verified bot and updated its security protocols to better detect and block similar stealth activity. The company describes these allegations as indicative of a broader challenge facing publishers and website operators as AI-driven content gathering grows in scale and sophistication.
Official Attribution and Statements
Cloudflare’s CEO labeled the practice an “existential threat” to publishers, emphasizing the importance of maintaining trust between website operators and technology platforms. In response to the accusations, a spokesperson for Perplexity disputed the findings, describing the report as a “publicity stunt” and claiming there were misunderstandings in the technical details presented.
Cloudflare has pledged to continue defending its customers’ preferences and website owners’ rights to control bot access, marking a new escalation in the debate over the ethical boundaries of AI web data collection.














{kind=link}
It is actually a nice and helpful piece of information. I’m glad that you shared this helpful info with us. Please stay us up to date like this. Thanks for sharing.